





{kind=link}
Decision tree machine learning is a predictive modeling tool which you can apply in many application to build artificial intelligence mechanism. It was based on several conditions to identify your answer by splitting data. Though it is very complex it works on the rules and filter model. It is one of the best applications of supervised learning to apply regression and classification analysis.
In Machine learning, you can use a decision tree for data mining and statistics as a predictive modeling algorithm. It can take the continuous value as input. Is a flowchart like structure to predict the decision. This non-pragmatic supervised machine learning model is used widely for regression and classification.
What is The Decision Tree in Machine Learning?
Decision tree in machine learning refers to a supervised machine learning method for all data are splits based on continuous interval on a certain parameter. It has two entity such as decision nodes and leaves. Each of the nodes and leaves represents conjunction and features. This flowchart like graphical presentation is applied in the real life of machine learning.
Why a Decision Tree is Used in Machine Learning?
A decision tree is non-pragmatic supervised learning. So it is used for many purposes in machine learning. Some of the purposes are:
- In the classification task, we use a decision tree.
- We also use it for regression tasks.
- To create a prediction model we use a decision tree.
- To make the optimal choice it is also good.
- For the information gain, we use it.
- If we need the sequential hierarchical decision will follow the mechanism of the decision tree.
The Data Format of The Decision Tree Machine Learning
The data format of the decision tree comes in a record form. We can Illustrate its examples:
(x, Y)=(x1,x2,x3,….,xk,Y)
In this example, Y is the dependent variable. So it is used for generalizing or classifying. The component “x” is a vector that has features of
x1,x2,x3, etc. That represents a task.
training_data = [
[‘Green’, 3, ‘Apple’],
[‘Yellow’, 3, ‘Apple’],
[‘Red’, 1, ‘Grape’],
[‘Red’, 1, ‘Grape’],
[‘Yellow’, 3, ‘Lemon’],
]
# Header = [“Color”, “diameter”, “Label”]
# The last column is the label.
# The first two columns are features.
Let’s Get the code of the example:

The Process Components to Make The Decision Tree
Decision tree machine learning follows some approaches to take the decision. Each of the nodes is backed by a question. Based on the question data scientist gather information based on the answer. Some of the processes to make a decision tree in machine learning are:
Information Gain
If you want to make a decision tree you have to gain the information. The recommendation is that should be small because it will make the system less complex. Information is known as measuring purity.
Asking a Question
To make the decision tree structure must follow the question-answer session. Is cancer is classified as a value that will help you classify the model? The answer can be yes/ no, right/ wrong, positive/negative 0/1 basis.
Gini Impurity
Which is the measurement of the likelihood of incorrect classification? Gini impurity has two parts like pure and impure. Your means the selected sample is from the same data class. if there is a mixture of different classes we can call it impure.
Steps in Making a Decision Tree Machine Learning
Decision tree in machine learning used for projecting and decision. To predict any decision you have to follow some steps in the environment of the decision tree. The steps of making the decision tree are:
Step 1: First of all you have to collect a set of data. The dataset is vital for making a decision tree.
Step 2: Now you have to measure the Gini impurity. App to find out the purity and impurity of the data set. The mixed data set will provide a different result.
Step 3: No identify your questions and generate a list for the nodes of the decision tree.
The answer to your question will be in two-state. It can be true/false, yes/no, 0/1.
Step 4: now calculate the information you have gathered based on your answer offer step 3.
Step 5: based on your question’s answer to update all of your information.
Step 6: get the best information ( higher information you received).
Step 7: divide your best question and repeat it from the first step until you receive pure information.
Advantage of Decision Tree
- The decision tree model is very easy to implement because it represents true false or if-else rules.
- in the same dataset, you can handle the data based on continuous feature or category feature.
- the method of making the decision tree is automatically selected.
- It can handle both categorical and numerical data.
- It is easy to add new features.
- On a large data set, you can use the model very effectively.
The Disadvantage of a Decision Tree
- The features of the decision tree is poor compared to other machine learning models.
- Sometimes the decision tree model suffered for instability.
- The decision tree has prone to overfitting.
- It is very sensitive to changing a small dataset.
- Some queries for the data scientist
- To develop a decision tree machine learning some questions in your mind. We will try to answer this question frequently asked question basis.
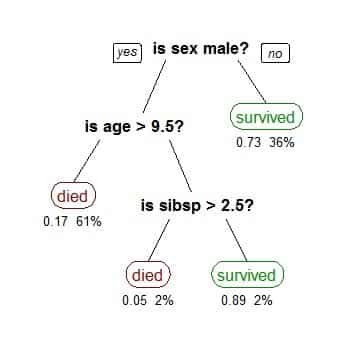
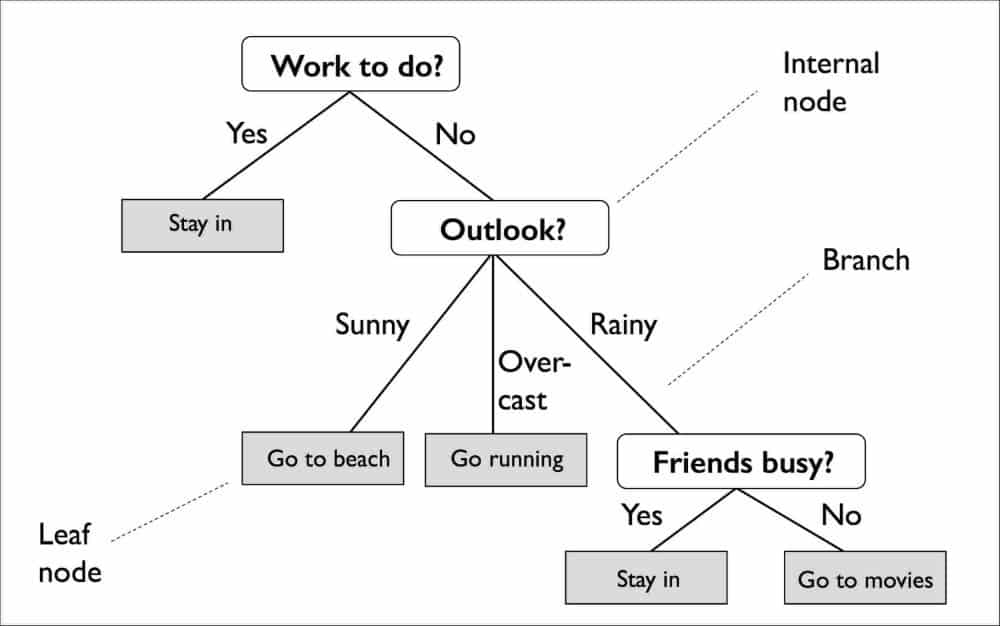
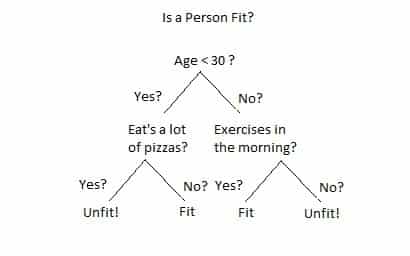
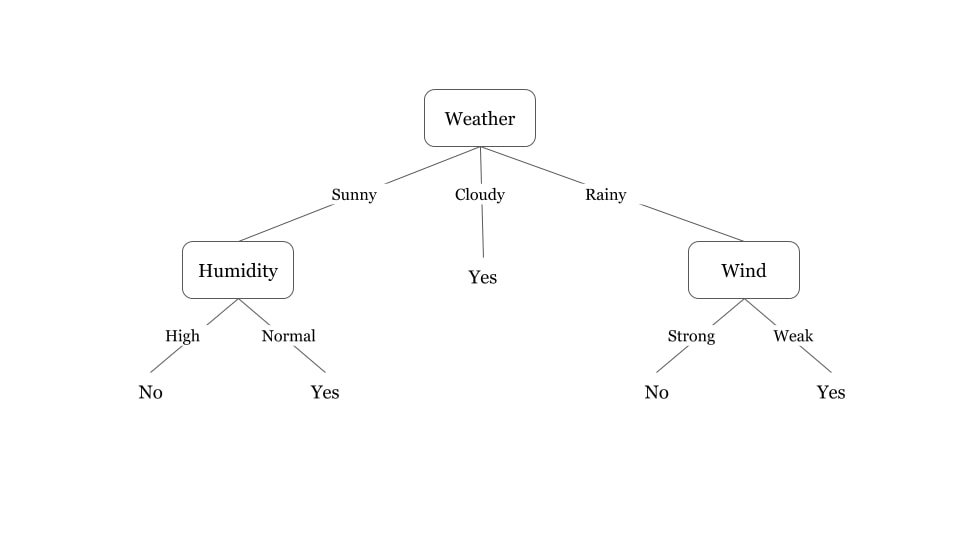
Real-life Application of Decision Tree
The decision tree is applied in many sectors of real life. Some of the examples is shown by the image.
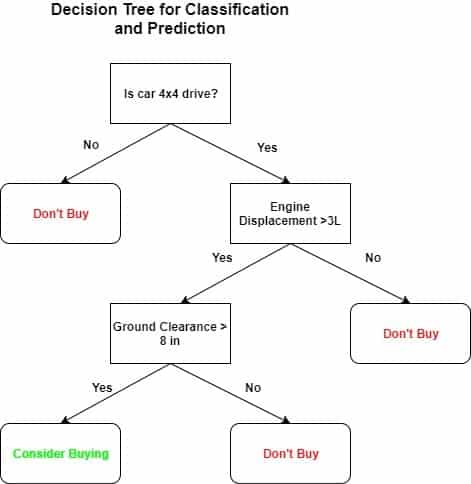
Decision Tree In Excel
If you are good at using Microsoft Excel you can develop a decision tree on MS Excel 2013. You will also be capable to make a flowchart with Excel. The main advantage of using Excel is is linking facility. You can hyperlink one row to another datasheet row. The general Excel you may not find the options for making a decision tree. You have to go for the options of Ad in.
Are Decision Tree Supervised Learning?
The Decision tree is non-pragmatic supervised learning but you can use it for unsupervised purposes. But there is a problem in supervision that it is incompatible with other machine learning techniques like deep neural networks for support vector machines.
What is The Final Objective of The Decision Tree?
The final objective of the decision tree is to make the optimal choice for each node. The algorithm is designed in such a way so that it is capable of doing the job. The algorithm is greedy and recursive. Generally, it is known as the hunt’s algorithm.
Why the Decision Tree is The Best Data Mining Algorithm?
The machine learning decision tree is the best data mining algorithm because of various reasons. It gathered data by splitting it. It also compares the values with another split. Some of the reasons for becoming the best are:
- There is no specific data distribution is required for the decision tree. So it is popularly known as non-pragmatic.
- Like any normal value, it can handle missing value so the mining procedure becomes easy.
- Elegant tweaking is possible in the decision tree. So you can choose the surrounding variables.
- It helps to reduce the number of variables. so it is one of the best independent variable selection algorithms of machine learning.
- It is very easy to understand so the weak learner’s data mining procedure easy to understand.
- It identified subgroups with lots of observation and variable.
- The decision tree is simple but provides a high-quality model.
Final Thought
The decision tree is one of the best machine learning models and algorithms to solve many real-life problems. Some data scientists considered it as one of the best data mining tool based on the non-pragmatic framework. the implementation of the decision tree is very easy and accurate. We can do many things with decision tree machine learning.
why not try these out largehand online