





{kind=link}
k nearest neighbor algorithm is a very simple and easy machine learning algorithm that is used for pattern recognition and finding the similarity. Out of the most effective machine learning tools, KNN follows the non-pragmatic technique for statistical estimation. It is a supervised machine learning model used for classification. Besides pattern recognition, the data scientist uses for intrusion detection, statical estimation, data mining.
K nearest neighbor is widely used in real-life scenarios. From medical science to the online store everywhere we use the K Nearest Neighbor Algorithm. It set a boundary and get the value based on the surrounding value. For the easy application, we use this algorithm.
Why You Use The K Nearest Neighbor Algorithm?
 We use machine learning for predicting any data. To predict data we use several models. K nearest neighbor is one of them.
We use machine learning for predicting any data. To predict data we use several models. K nearest neighbor is one of them.
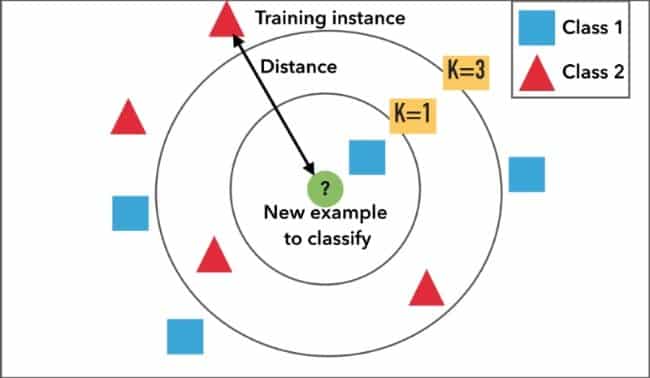
Now let us discuss how will we use the K Nearest Neighbor Algorithm. Suppose you have shown a picture of the cat to the machine. When you ask is it to get a dog, the system will tell you it is a cat.
It happens based on prediction. The machine takes several photos of cats and a dog. By several images, it makes a prediction. When you show any images, its answer is your questions based on the nearest value.
All of us have uses the Amazon website for purchasing our favorite items. When we search for any product it shows that product and it also shows some recommendations for another product. Machine learning your choices and shows your recommendation based on K Nearest Neighbor.
What is The K Nearest Neighbor Algorithm?
KNN or K Nearest Neighbor Algorithm is one of the best supervised easy algorithms of machine learning which is used for data classification. Best on neighbor’s classification it classifieds its data. It stores all available cases and classifiers including the new cases based on a similarity measure. For example, if someone likes normal juice or fresh juice it will depend on the value of the nearest neighbor. As a user, you have to who declared the value of k. Suppose the value of k is 5 then it will consider the nearest 5 value of a product. Based on the majority ratio it will predict your choice.
How the KNN Algorithm Works
Consider a dataset having two variables and height. Each of the points is classified as normal and underweight. No I giving a data set:
| Height | Weight | Weight |
| 167 | 68 | Normal |
| 165 | 75 | Overweight |
| 170 | 60 | Underweight |
| 150 | 65 | Normal |
| 160 | 40 | Underweight |
Now if I give the value of 157 cm height. The data is not given previously. Based on the nearest value it predicts the weight of 157 cm. It is using the model of k nearest neighbor.
We can implement the k nearest neighbor algorithm bye by Euclidean distance formula. It works by determining the distance of two coordinates. In a graph, if we plot the value of (x,y) and (a,b) then we will implication the formula as:
dost(d) = ✓(x-a)^2 + (y-b)^2
What is K?
K nearest neighbor ‘K” is a constant defined by users. At the query or test point, it is an unleveled vector. It classifies to assign the most frequent level among the K training sample nearest to the value of the query point. K is the imaginary boundary to classify the data. When the machine finds the new data it tries to find value withing or surrounding the boundary.
Finding the value of K is very difficult. If the value of k is small that means the noise has a high influence on the outcome. The value of K has a strong effect on the performance of KNN. In simple language, it is a similar thing nearest to others.
Is K Nearest Neighbor is a Lazy Algorithm
The data scientist considered the KNN is the lazy algorithm among other machine learning model. Someone considered it because lazy because it is easy to learn. It does not learn a discriminative function but “memorizes” the training dataset. The regression algorithm or any tool needs training time but KNN does not require the training time. So, it is considered a lazy algorithm.
How to Set the Value of K?
K nearest neighbor algorithm is based on the feature of similarity. Selecting the value of k is not easy. The process of selecting the value of k is called parameter tuning. To make the result accurate it is very important.

In this image, we can see the value of X1 and X2. The value of Red Star is independent. Now, we have to take three nearest values of the same distance. We get only one yellow dot. But, if we set the k value equals 6 then we will get two yellow dots and one another dot.
We can set the value of k to any odd number. The value of k may be 3,5, 7,9, 11 or any odd number. When you select the value of k = 3 you will get a specific answer. But if the value of k = 5 then the prediction may be changed. The result is based on the neighbor of your surroundings.
So, to choose the value of k:
- Smart(n), here we consider the value of n equals the total number of data points.
- To avoid any confusion between two numbers or points we always use an odd number.
When We Use The k Nearest Neighbor Algorithm?
You can use the k nearest neighbor algorithm labeled. In our supervised machine learning, we have seen the main requirement of it is data labeling. According to our previous example, we want to go for another example. The machine takes input based on several leveling. If you show the image of the cat it will contain height, weight, dimension, and many other features.
When the data set is normal and very small then we use k nearest neighbor algorithm. It does not alarm a discriminative function from that can you set. So it is known as a lazy learner algorithm.
Application of K Nearest Neighbor Algorithm?
K-nearest algorithm is used in various sectors of day to day life. It is easy to use so that data scientists and the beginner of machine learning use this algorithm for a simple task. Some of the uses of the k nearest neighbor algorithm are:
Finding diabetics ratio
Diabetes diseases are based on age, health condition, family tradition, and food habits. But is a particular locality we can judge the ratio of diabetes based on the K Nearest Neighbor Algorithm. If you figure out the data of is age, pregnancies, glucose, blood pressure, skin thickness, insulin, body mass index and other required data we can easily plot the probability of diabetes at a certain age.
Recommendation System
If we search any product to any online store it will show the product. Decide that particular product it recommends some other product. You will be astonished after knowing that the 35% revenue of Amazon comes from the recommendation system. Decide the online store, YouTube, Netflix, and all search engines use the algorithms of k-nearest neighbor.
Concept Search
Concept search is the industrial application of the K Nearest Neighbor Algorithm. It means searching for similar documents simultaneously. The data on the internet is increasing every single second. The main problem is extracting concepts from the large set of databases. K-nearest neighbor helps to find the concept from the simple approach.
Finding The Ratio of Breast Cancer
In the medical sector, the KNN algorithm is widely used. It is used to predict breast cancer. Here KNN algorithm is used as the classifier. The K nearest neighbor is the easiest algorithm to apply here. Based on the previous history of the locality, age and other conditions KNN is suitable for labeled data.
Is K Nearest Neighbor Unsupervised?
No, KNN is supervised machine learning. The K-means is an unsupervised learning method but KNN always uses correlation or regression. In unsupervised learning, the data is not labeled but K nearest neighbor algorithm always works on labeled data.
KNN in Regression
Besides classification, KNN is used for regression. It considered the continuous value of the KNN algorithm. The weighted average of the k nearest neighbors is used by Mahalanobis distance or Compute the Euclidean method.
Advantage of K Nearest Neighbor
KNN algorithm is very easy to use. For lazy learners, it is the best algorithm to apply in machine learning. It has some benefits which are as follow:
- KNN algorithm is very easy to learn.
- For the distance or feature choice, it is flexible.
- It can handle multi-class cases.
- With enough representative data, it can do well in practice.
Limitation of KNN Algorithm
- If you want to determine the nearest value you have to set the parameter value k.
- The computation cost of the KNN algorithm is very high.
- It computes the distance of each query for all training samples.
- Storage of data is another problem.
- As a user, you must have to know meaningful distance functions.
Final Thought
K Nearest Neighbor Algorithm works based on labeled data. To calculate the value of prediction the value of k is predefined. Now KNN finds the value based on the nearest neighbor or surrounding value. The dataset of this algorithm is very small and works on labeled data. It is very easy to use. Because of its characteristics, it is known as the lazy algorithm of machine learning.